S3 is the perfect place to store data, until you try to search it.
This project started when I read a tweet mentioning Turbopuffer and ParadeDB. Both were new to me, so I went and read up on them. Turbopuffer is a serverless vector and full-text search database built on object storage. Apparently, it handles over 3.5 trillion documents and 10 million writes per second in production.
This sounded great to me as I have a mini obsession with making data related tools backed by s3 and I know performance can be a blocker. I went looking for a way to self-host it with no luck. Turbopuffer is closed-source and SaaS-only, no free tier and no open-source version.
That was a shame, but it confirmed to me that using S3 could be a viable and performant solution since an existing company was already doing it. My day job is creating and managing infrastructure. I like to keep costs down too, which can often be at odds with one another. That’s what makes S3-backed approaches attractive to me.
In the past, I tried to use S3 as a logging solution to try to avoid the cost of third-party solutions: “Using a combination of Vector.dev (a logging agent), WarpStream (a Kafka-compatible data streaming platform) and Apache Flink (a distributed processing engine) can provide a hugely cost-effective and powerful logging solution worth looking at.”
Recently I developed Notebare.com, a basic task list app for my own use that stores data in Lance format on S3. I made it this way to learn about Lance and see what its performance was like as a backend on S3. Understandably it wasn’t great. I moved it to S3 Express One Zone and performance improved a lot. I continue to use Notebare for my own task lists.
Turbopuffer really sounded great. Vector and full-text search on object storage with good performance. I went looking for open-source alternatives and didn’t find any. Turbopuffer’s architecture is fairly novel, the combination of three things in one service: vector search, full-text/BM25 search, and an object-storage-native architecture with intelligent SSD and RAM caching. Not many projects combine all three.
I was already using Lance from S3, so I wondered if adding a cache would help significantly. I had bookmarked a cache on GitHub called foyer in the past and started to work on it to see if an API + foyer + Lance on S3 would work.
I needed an API, and since speed was a goal, I looked for fast API frameworks and found axum, a “HTTP routing and request-handling library for Rust that focuses on ergonomics and modularity.”
I knew starting off that there would be at least 2 hard problems to solve before ever getting to performance. That is being able to clear a cache when needed, and conditional writes. These are important because without a way to clear the cache, search results can return stale data that doesn’t reflect what’s actually in S3.
But foyer doesn’t support “delete-by-prefix,” and I didn’t want my app to spend seconds scanning the data every time a user hit save. I ended up using a generation counter, a per-tenant value that is bumped on every write. It doesn’t spend time deleting the old cache entries; it just makes them unreachable by key at a constant speed that won’t slow down as data grows.
For conditional writes, I didn’t want to add an extra database or locking service just to track state. Instead, I relied on S3’s If-None-Match: * header to act as a lock. This ensures that if two writers fight over the same namespace, only one wins. That prevents data from being silently overwritten. That’s the kind of bug that makes everything look fine while your data is actually disappearing.
I put the parts together in Docker Compose. MinIO for S3-like storage and the API I was creating with Axum. I used this to confirm that the generation counter and conditional writes worked as expected.
I started to make API endpoints for upsert and query to start testing performance. At first, searches were taking 25 seconds because S3 was scanning every single vector.
Adding an index in Lance brought that down to about 1 second, which was better but not instant even with a small data set. The magic happened when I added in the foyer cache. By skipping the trip to S3 entirely for hot data, that 1-second wait dropped to 72 microseconds for recurring searches. A brand-new query still pays the full Lance-on-S3 cost the first time because the cache is keyed by query hash. It only helps once a query has been seen before. That’s fine for certain workloads where the same handful of searches make up most of the traffic.
Even with a fast cache, there was another S3-specific wall I eventually hit: the “Fragment Problem.” Every time you save data, Lance appends a new file to S3. If you save 500 times, a single search has to open 500 files just to find the answer. S3 performance will die there. To solve this, I added a /compact endpoint. It merges those hundreds of tiny fragments into a few large, optimized files.
Repeat searches started coming back in 72 microseconds instead of 25 seconds. I was delighted. I posted about Firn on Twitter and got some great feedback.
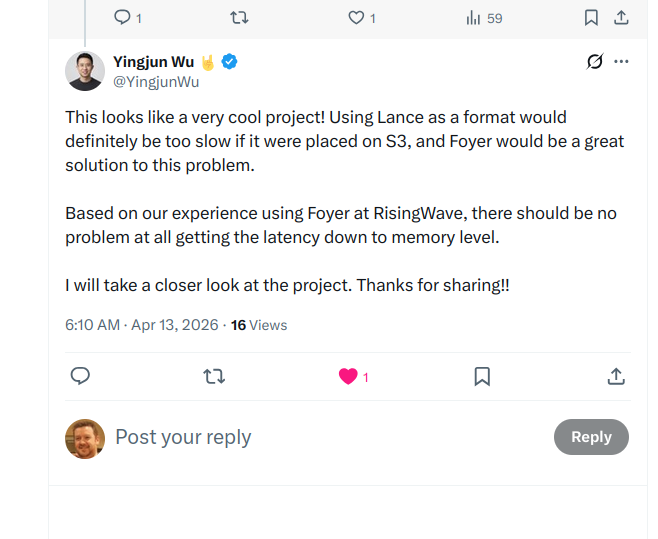
One reply stood out. Yingjun Wu, founder of RisingWave, commented that using Lance as a format would be too slow placed directly on S3, and that foyer would be a great solution to the problem. He added that based on RisingWave’s experience using foyer in production, there should be no problem getting latency down to memory level. That meant a lot. foyer was built inside RisingWave to solve exactly this problem of S3 latency!
Over a few days, different people asked about other object stores such as Google. This was great; I learned of object stores I’d never heard of before like Backblaze B2, Tigris, and was reminded of object stores I’d forgotten about like DigitalOcean Spaces. Each one was an opportunity to test Firn with a different backend. I ran the same tests with each one, specifically the 2 main tests needed to pass for each: a sequential conditional-PUT pre-flight (to see if the provider actually respects the header) and an 8-writer concurrent stress test (to make sure they don’t lose data when multiple people write at once).
I found that Google Cloud Storage silently ignores conditional writes, while Cloudflare R2 and Tigris handle them correctly.
| Provider | Supported | Reason |
|---|---|---|
| AWS S3 | ✅ | Strict CAS, clean pass on 100-run stress. |
| MinIO | ✅ | Reference implementation for the S3 protocol; clean pass on 100-run stress. |
| Cloudflare R2 | ✅ | If-None-Match: * honoured correctly; 100-run stress clean. |
| Backblaze B2 | ❌ | Returns HTTP 501 NotImplemented on the first PutObject with If-None-Match: *. |
| Tigris | ✅ | If-None-Match: * honoured on concurrent commits; 100-run stress clean. |
| DigitalOcean Spaces | ✅ | Strict CAS, 100-run stress clean. |
| Google Cloud Storage | ❌ | Silently ignores If-None-Match: *: second conditional PUT returns 200 OK. |
Tigris was the most interesting one. The first run failed. The pre-flight passed fine, but the 8-writer concurrent stress test was losing rows on both their dual-region and single-region buckets. That’s exactly the failure mode I was most worried about, the kind that looks fine in dev and silently corrupts data in production. I posted about it on Twitter on a Friday, expecting the issue to take a while to be addressed. Instead, Ovais Tariq from Tigris saw it, dug into their implementation over the weekend, and shipped a fix by Sunday. I re-ran the same 100-iteration stress test against the patched build on Monday, and it came back 100/100. That kind of turnaround over a weekend from a vendor I had no relationship with is a great outcome.
From here, I added some features to make the API more usable, such as a /list endpoint to get recent rows. There was no point in having an API if an application needed to go around it for a simple list of recent data.
I also realized that having a global FIRNFLOW_VECTOR_DIM setting was a mistake. It meant the whole server was locked to one model’s size. I replaced that with automatic schema inference. Now, Firn discovers the vector dimension from the first write or by reading the existing S3 manifest. This means a single Firn instance can host totally different tenants like a 128-dim image search and a 1536-dim text search, side-by-side without any complex configuration.
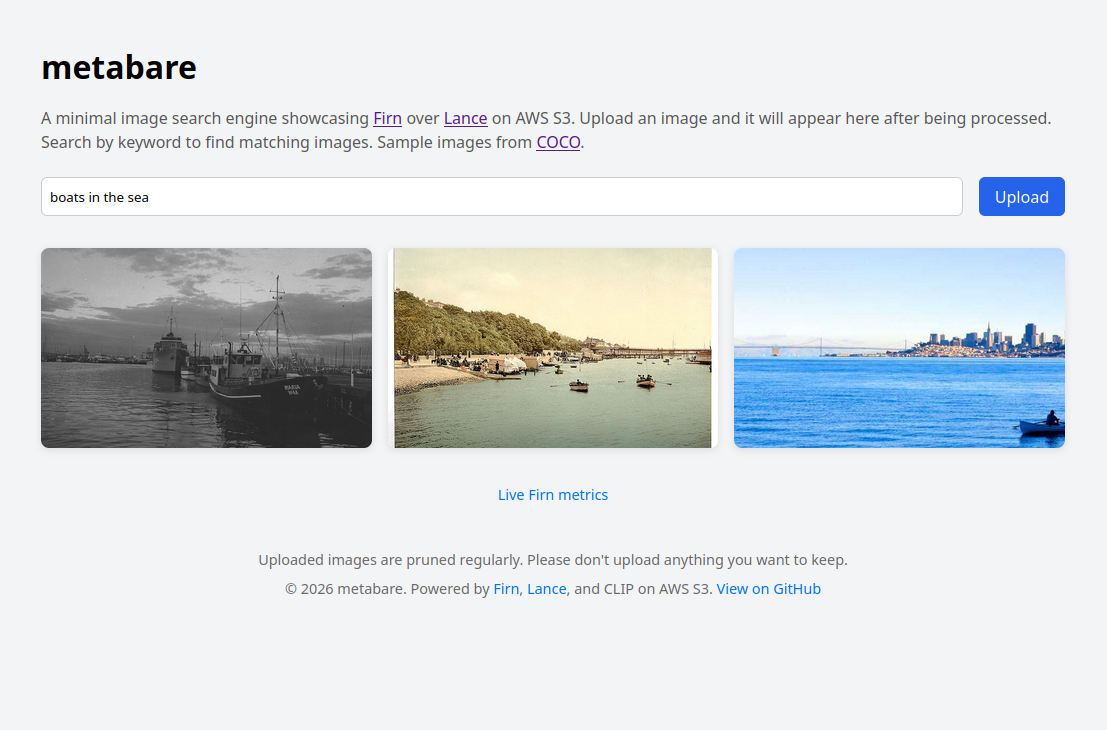
Another project I made a while back was Metabare.com, a minimal image search engine. It originally used Lance on local EBS storage, which worked but wasn’t very cost-effective for a small side project. I’ve since moved it to use Firn as its backend. It’s both a working example and a showcase.
Firn exposes metrics that are visible in Grafana too, so it’s clear exactly which searches are hitting the cache and which are fetching fresh data from S3.
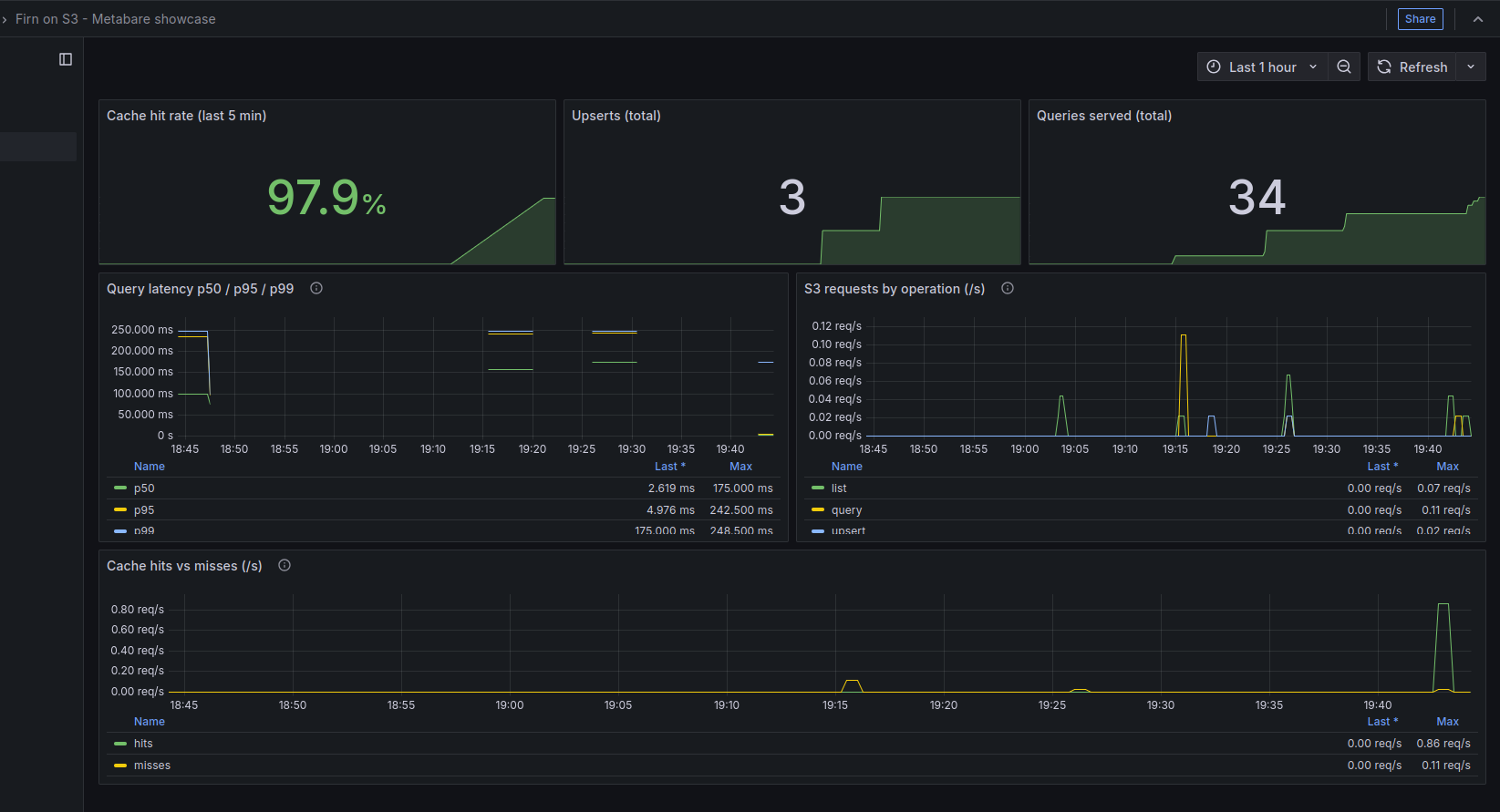
In the end, this project came back to my day job of managing infrastructure costs. High performance is great, but in the cloud, that can get expensive fast. I built the cache as much for cost as for speed. By exposing Prometheus metrics like s3_requests_total, it’s clear exactly how much traffic is being blocked from ever hitting S3. Every cache hit is also a direct reduction in the monthly S3 bill. It’s a way to have high performance search results without the likely high cost of a solution such as Opensearch.
There is still more to do. I want to move away from manually triggering indexes and compaction. Features like auto-indexing after N rows and background compaction will make Firn even more of a solution for developers who want the cost benefits of S3 without the management overhead.
S3 is still the perfect place to store data. It turns out, with the right cache in front of it, you can search it too!
Firn is open source on GitHub: github.com/gordonmurray/firnflow.