From a custom Flink connector to a $600k windfall: Building a 6-tier streaming lakehouse
I’ve been working on a data engineering pipeline lately to see if I could build a high-throughput system without touching a single traditional database. It started as an investigation into Apache Iggy, a new Rust-based alternative to Kafka that focuses on performance and simplicity.
Running Iggy on its own doesn’t do much, so I added Apache Flink to read from its topics. But Flink didn’t have a connector for Iggy yet for the version of Flink I am using. I used a spec-driven approach to build one in an evening, and it worked so well that an Iggy maintainer suggested migrating it into their official open-source repo.
You can find the connector here: flink-connector-iggy and the full quickstart project here: flink-iggy-quickstart.
With the connector working, I needed a busy data source to actually stress the pipeline. Crypto price ticks are perfect for this: they’re high-volume, structured, constant, and free via a Coinbase WebSocket. Once real data was flowing, the project grew organically.
The 6-tier architecture
The goal was to handle a live firehose of crypto price ticks from Coinbase, processing six pairs (BTC, ETH, SOL, DOGE, AVAX, and LINK) through a tiered storage setup.
┌─────────────────────────────────────────────────────────────────────┐
│ DATA SOURCES │
│ Coinbase Exchange Public WebSocket (wss://ws-feed.exchange...) │
│ 6 pairs: BTC, ETH, SOL, DOGE, AVAX, LINK — sub-second ticks │
└──────────────────────┬──────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ POLLER (Python Ingestion) │
│ Persistent WebSocket. Normalises ticks → Iggy topic crypto/prices │
└──────────────────────┬──────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ IGGY BROKER │
│ Event spine. Topics: crypto/prices, crypto/orders, crypto/replay │
│ Persistent storage at /app/local_data/ (bind-mounted to host) │
└───┬──────────┬───────────┬───────────┬──────────────────────────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌────────┐ ┌────────┐ ┌────────┐ ┌────────────────────────────────────┐
│BRIDGE │ │LANCER │ │REPLAY │ │ APACHE FLINK │
│Iggy → │ │Signal │ │Iceberg │ │ 3 streaming jobs (HA via ZK): │
│Prom │ │Mode │ │→ Iggy │ │ │
│metrics │ │(live) │ │(on │ │ 1. Lakehouse: Iggy → Paimon OHLCV │
└───┬────┘ └───┬────┘ │demand) │ │ + Iceberg tick archive │
│ │ └────────┘ │ 2. Hot tier: Iggy → Fluss ticks │
▼ │ │ 3. Clearing house: Iggy orders → │
┌────────┐ │ │ Paimon balance/trades + Fluss │
│GRAFANA │ │ └──────┬─────────┬───────────────────┘
│5 dash- │ │ │ │
│boards │ │ ▼ ▼
│candle- │ │ ┌────────────┐ ┌───────────────┐
│sticks │ │ │ PAIMON │ │ ICEBERG │
└───▲────┘ │ │ (Warm) │ │ (Cold) │
│ │ │ ohlcv_1m │ │ Raw ticks │
│ │ │ balance │ │ Time-travel │
│ │ │ trades │ │ Replay source │
│ │ └──────┬─────┘ └───────────────┘
│ │ │
│ │ ▼
│ │ ┌──────────────────┐
│ │ │ RECONCILIATION │
│ │ │ Host cron script │
│ │ │ Flink SQL → JSON │
│ │ │ (every 5 min) │
│ │ └────────┬─────────┘
│ │ │
│ ▼ ▼
│ ┌────────────┐ ┌──────────────────────┐
│ │ LANCEDB │ │ CONSENSUS ENGINE │
│ │ Vector │────▶│ (Paper Trading) │
│ │ patterns │ │ Signals + Ledger │
│ │ 38K+ │ │ → Iggy orders │
│ └────────────┘ └──────────┬───────────┘
│ │
│ ┌────────────┐ │
│ │ ANALYST │────────────────┘
│ │ Ollama │ sentiment signals
│ │ LLM │
│ └────────────┘
│ │
└──────────┘ annotations
- Apache Iggy: The message spine. In my stress tests, a single Rust binary handled over 12,000 messages per second with less than 2ms latency and under 6% CPU usage. A far cry from the JVM tuning and ZooKeeper overhead I dealt with in Kafka.
- Apache Flink: The main compute engine. It runs three streaming jobs in HA mode, handling everything from 1-minute OHLCV (Open, High, Low, Close, Volume) candle aggregation to the clearing house for trades.
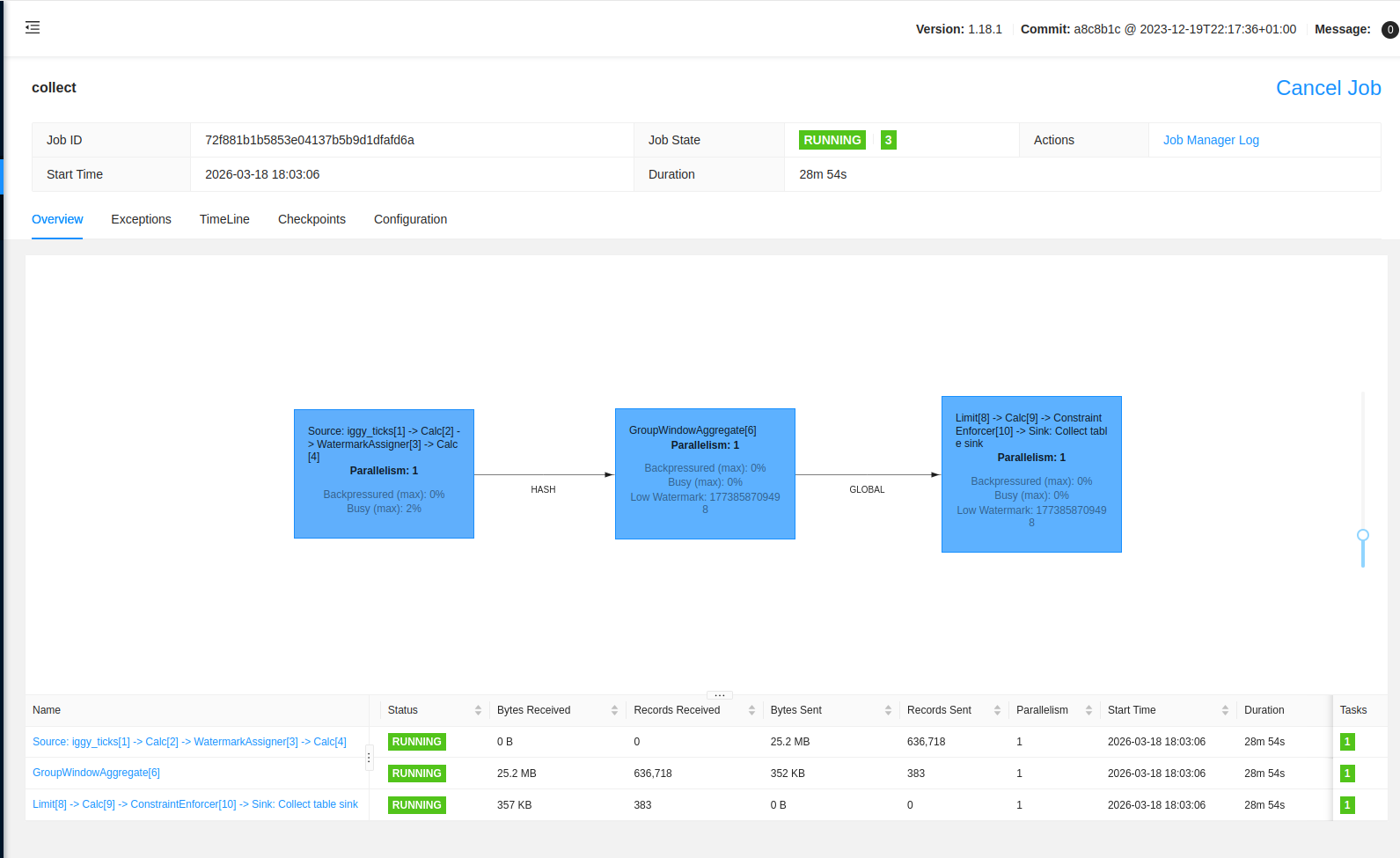
- Apache Fluss: A streaming storage tier for sub-second SQL queries. I used it to hold the live ticks so I could query the current market state with standard SQL at much lower latency than a traditional DB. I’ve explored this combination before in a previous project, apache_fluss_flink_and_paimon.
- Apache Paimon: The warm tier, and where the engineering got most interesting. Paimon isn’t just a table format. Its Merge Engines change how you think about writes. For the trading ledger, I used the Aggregation Engine: every INSERT is a delta (like
-100 USD), and Paimon sums them on the fly to produce a real-time balance without ever needing a costly read-then-write. I also used the Deduplication Engine for trade history and append-only mode for fast candle generation. I’ve put together a smaller apache_flink_and_paimon repo previously that shows the basics. - Apache Iceberg: The cold archive. Every raw tick from the Coinbase firehose is stored here, partitioned by day and compressed with Zstandard. Because Iceberg supports deterministic snapshots, I can point a replay engine at any point in history and pump those raw ticks back into Iggy at 60x speed to test new trading strategies on the exact same pipeline they would face in production. I’ve used Iceberg in projects like apache_flink_and_iceberg before, but this is the first time I’ve used it as a replay source rather than just a warehouse.
- LanceDB: This stores the vectorized price patterns so I can find historical market similarities in real-time.
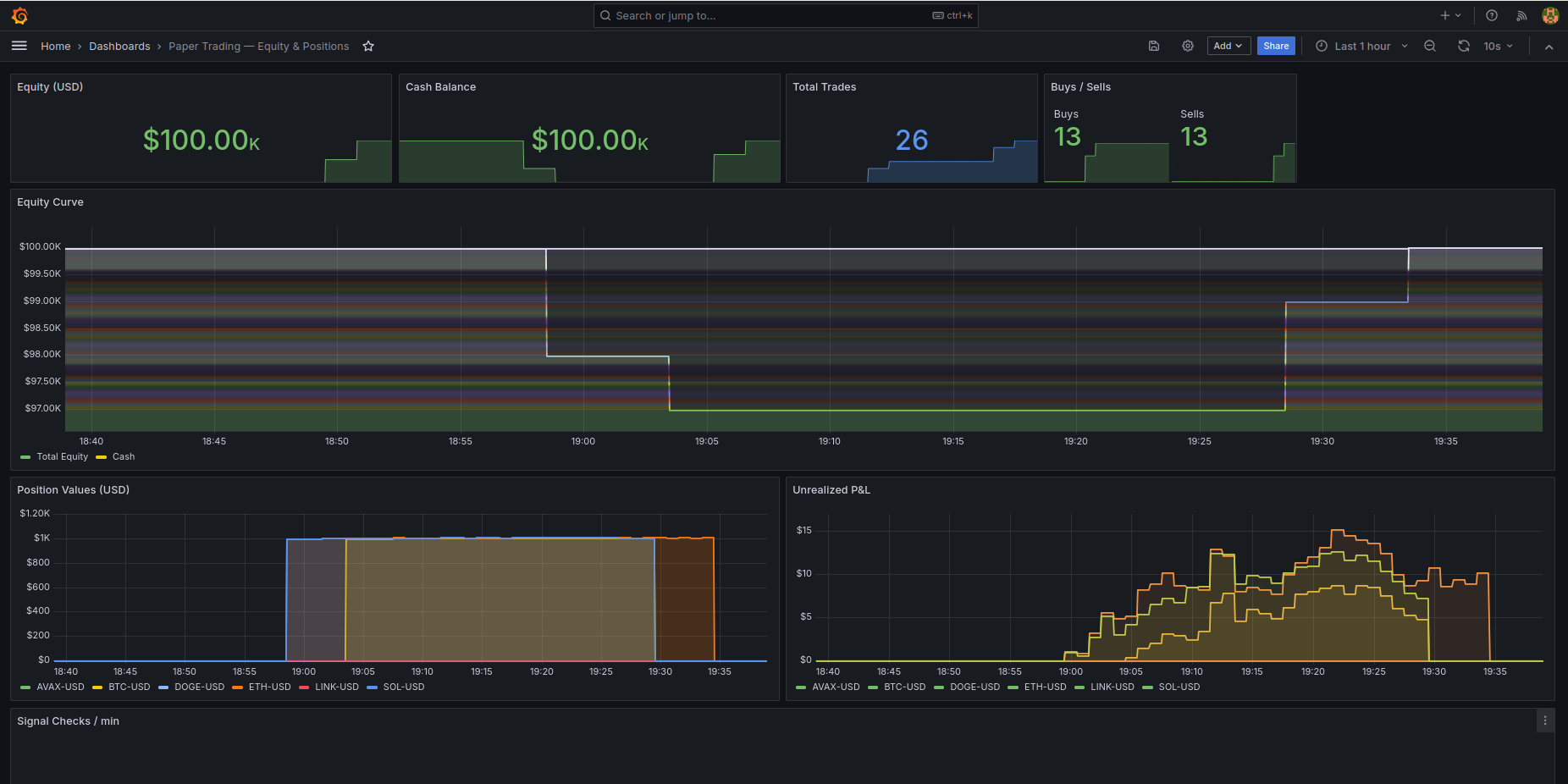
What went wrong: The $600k windfall
The most interesting part of this build was when the account balance suddenly tripled overnight. I wasn’t using real money, but seeing a $600k jump in a paper trading account makes you look at the ledger very closely. It turned out to be a few subtle issues with how streaming systems handle state.
The first problem was Paimon’s aggregation engine. In a traditional database, an INSERT is a fact. In Paimon, an INSERT is an instruction to add an amount to the running total. I had manually submitted a seed job to add $100k a few times while debugging, and every time Flink resumed the job, it applied the delta again. If your storage layer uses delta semantics, your ingestion has to be strictly idempotent, or you get lovely increased balances.
The second was Flink HA being good at its job. Even after I stopped manual submissions, the balance jumped again. Flink HA persists the job graph in ZooKeeper, and when the cluster restarted, it recovered a one-shot seed job that had already finished. The job came back, ran once more, and added another $100k. One-shot jobs need to be explicitly flushed from ZooKeeper after completion, or HA will do its job and resurrect them.
The third was a mismatch between DuckDB and Paimon. My balance looked correct in Flink SQL but showed $300k in my Grafana dashboard, which used DuckDB. I was using duckdb.read_parquet() on the Paimon directory and didn’t realise that Paimon keeps old delta files on disk even after writing a compacted snapshot. Flink SQL reads the manifest to know which files are current, but DuckDB was reading every parquet file in the folder, summing the past and the present at the same time. A lakehouse table is a managed state, not just a folder of files. If your reader doesn’t understand the manifest, it will happily read everything.
Pattern matching and AI annotations
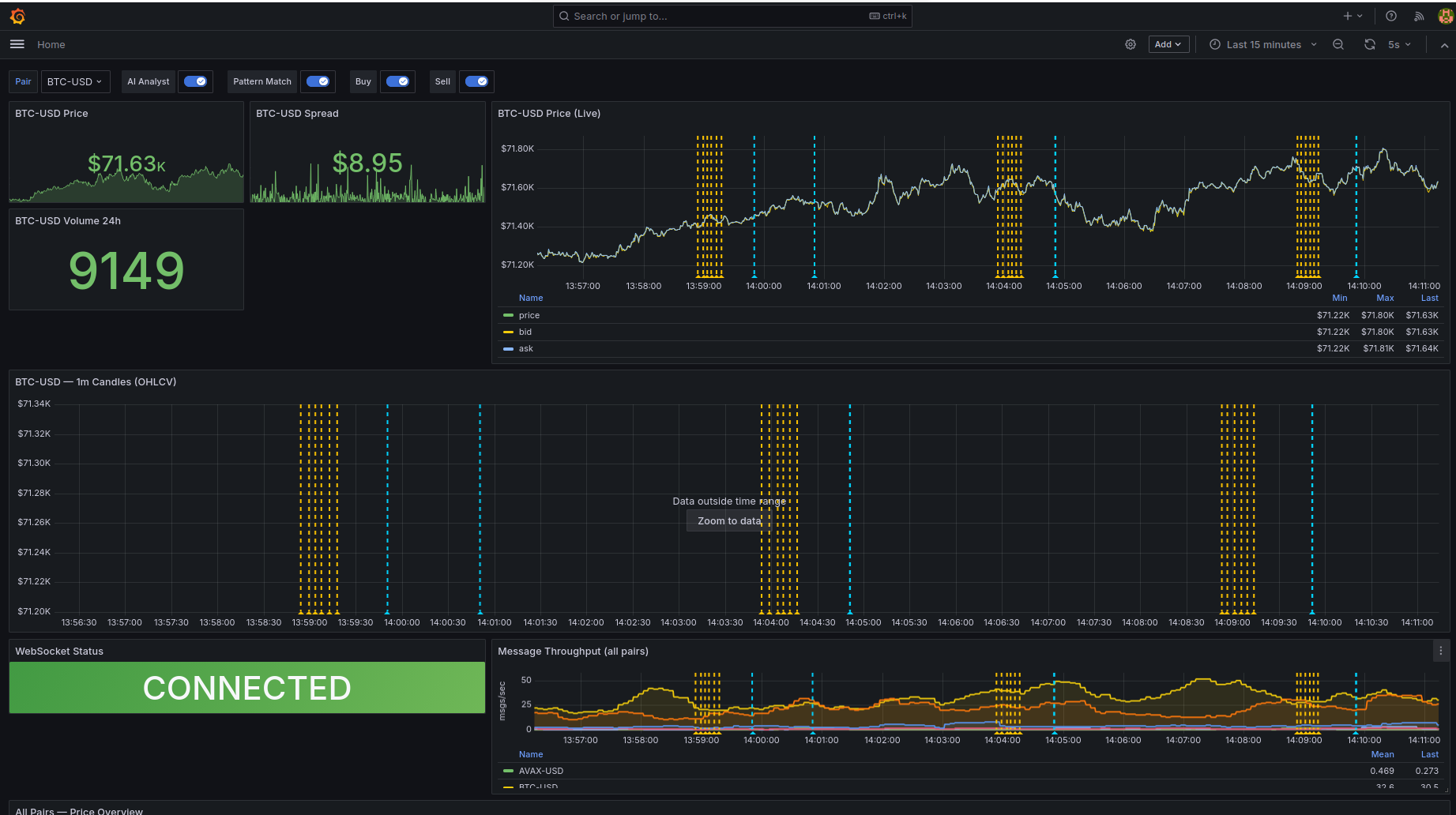
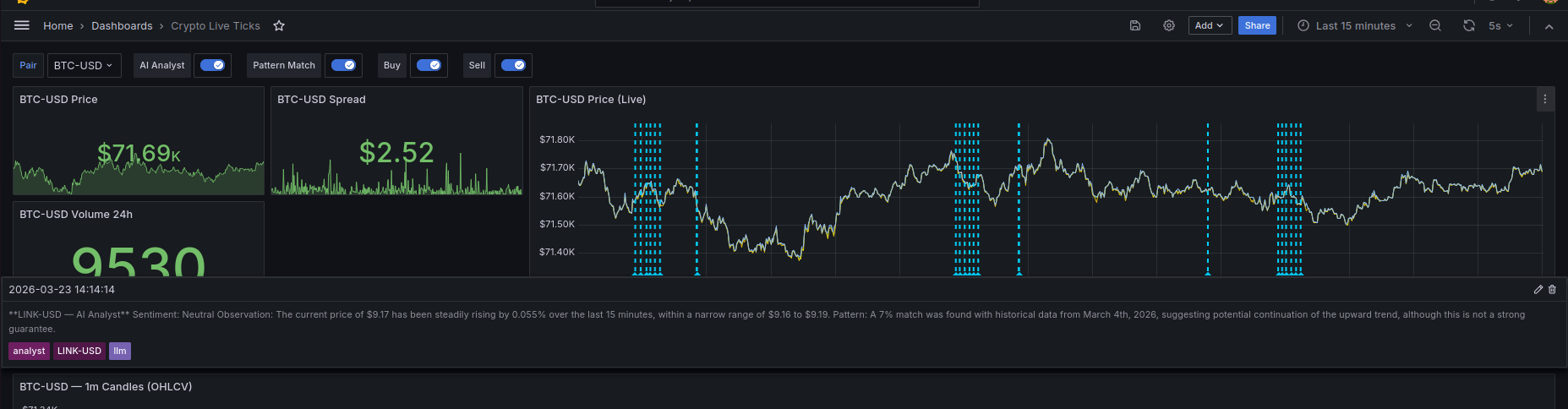
I used LanceDB to find historical similarities by vectorizing 60-minute segments of 1-minute candles using Z-score normalization. This strips away the absolute dollar value and only looks at the movement, so a 10% move looks the same whether Bitcoin is at $100 or $100,000. When live action hits the stream, the system vectorizes the last hour and asks LanceDB to show the top historical matches and what happened to the price afterwards.
I also integrated a local LLM, Llama 3.2 via Ollama, directly into the observability layer. Every 5 minutes, an analyst service pulls context from Prometheus price trends and LanceDB matches to build a prompt. For example, it might see BTC-USD at 64,200 with a 1.2% trend and a 89% similarity to a previous bull flag pattern.
The output is pushed to Grafana as a yellow annotation. So when you see a price spike on the chart, you also see a note explaining that this pattern historically led to a breakout most of the time.
Trade-offs and future ideas
Running a 6-tier stack on a single machine has a lot of operational overhead. Six JVMs and a Rust broker in Docker Compose is a heavy lift and requires resource limits so the ingestion doesn’t lag. If I were doing this again, I’d consider a different approach. Keeping Paimon, Iceberg, and Fluss in sync is a bit of a headache, but an interesting challenge and a good opportunity to learn more.
While I built this for crypto, the pattern of high-speed intake, real-time analysis, and tiered archiving is a solid fit for things like cloud security or fraud detection. You could vectorize user API calls in AWS CloudTrail to flag when a user’s behaviour deviates from their historical baseline in real-time. For now, it’s a good proof of concept that you can build a robust, intelligent data platform without a traditional database.